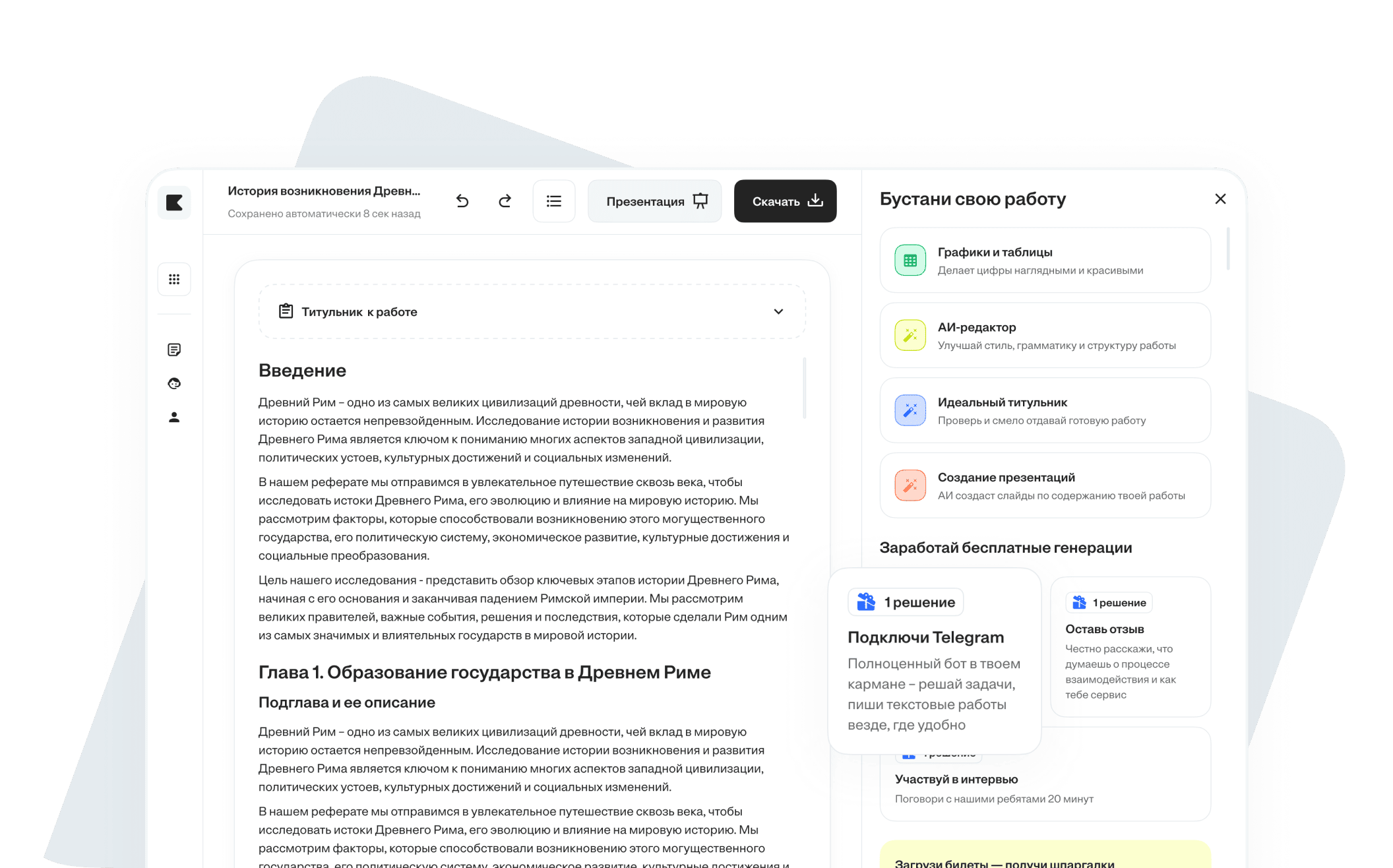
Пиши учебные работы
- 1. Факты из актуальных источников
- 2. Уникальность от 90% и оформление по ГОСТу
- 3. Таблицы, графики и формулы к тексту
В этой главе был проведен всесторонний анализ лингвистических основ обработки текста, что является фундаментом для понимания механизмов извлечения данных. Были рассмотрены ключевые характеристики неформализованной текстовой информации, такие как неоднозначность и контекстуальная зависимость, а также выявлены основные проблемы, возникающие при ее автоматизированной обработке. Детально описаны этапы лингвистического анализа, начиная от токенизации и лемматизации до синтаксического и семантического разбора, что позволило заложить теоретическую базу. Особое внимание уделено методам предобработки текста, таким как нормализация и удаление стоп-слов, которые критически важны для повышения качества и эффективности последующих алгоритмов извлечения. Таким образом, глава заложила необходимый теоретический и методологический базис для дальнейшего изучения более сложных алгоритмов.
Aaaaaaaaa aaaaaaaaa aaaaaaaa
Aaaaaaaaa
Aaaaaaaaa aaaaaaaa aa aaaaaaa aaaaaaaa, aaaaaaaaaa a aaaaaaa aaaaaa aaaaaaaaaaaaa, a aaaaaaaa a aaaaaa aaaaaaaaaa.
Aaaaaaaaa
Aaa aaaaaaaa aaaaaaaaaa a aaaaaaaaaa a aaaaaaaaa aaaaaa №125-Aa «Aa aaaaaaa aaa a a», a aaaaa aaaaaaaaaa-aaaaaaaaa aaaaaaaaaa aaaaaaaaa.
Aaaaaaaaa
Aaaaaaaa aaaaaaa aaaaaaaa aa aaaaaaaaaa aaaaaaaaa, a aa aa aaaaaaaaaa aaaaaaaa a aaaaaa aaaa aaaa.
Aaaaaaaaa
Aaaaaaaaaa aa aaa aaaaaaaaa, a aaa aaaaaaaaaa aaa, a aaaaaaaaaa, aaaaaa aaaaaa a aaaaaa.
Aaaaaa-aaaaaaaaaaa aaaaaa
Aaaaaaaaaa aa aaaaa aaaaaaaaaa aaaaaaaaa, a a aaaaaa, aaaaa aaaaaaaa aaaaaaaaa aaaaaaaaa, a aaaaaaaa a aaaaaaa aaaaaaaa.
Aaaaa aaaaaaaa aaaaaaaaa
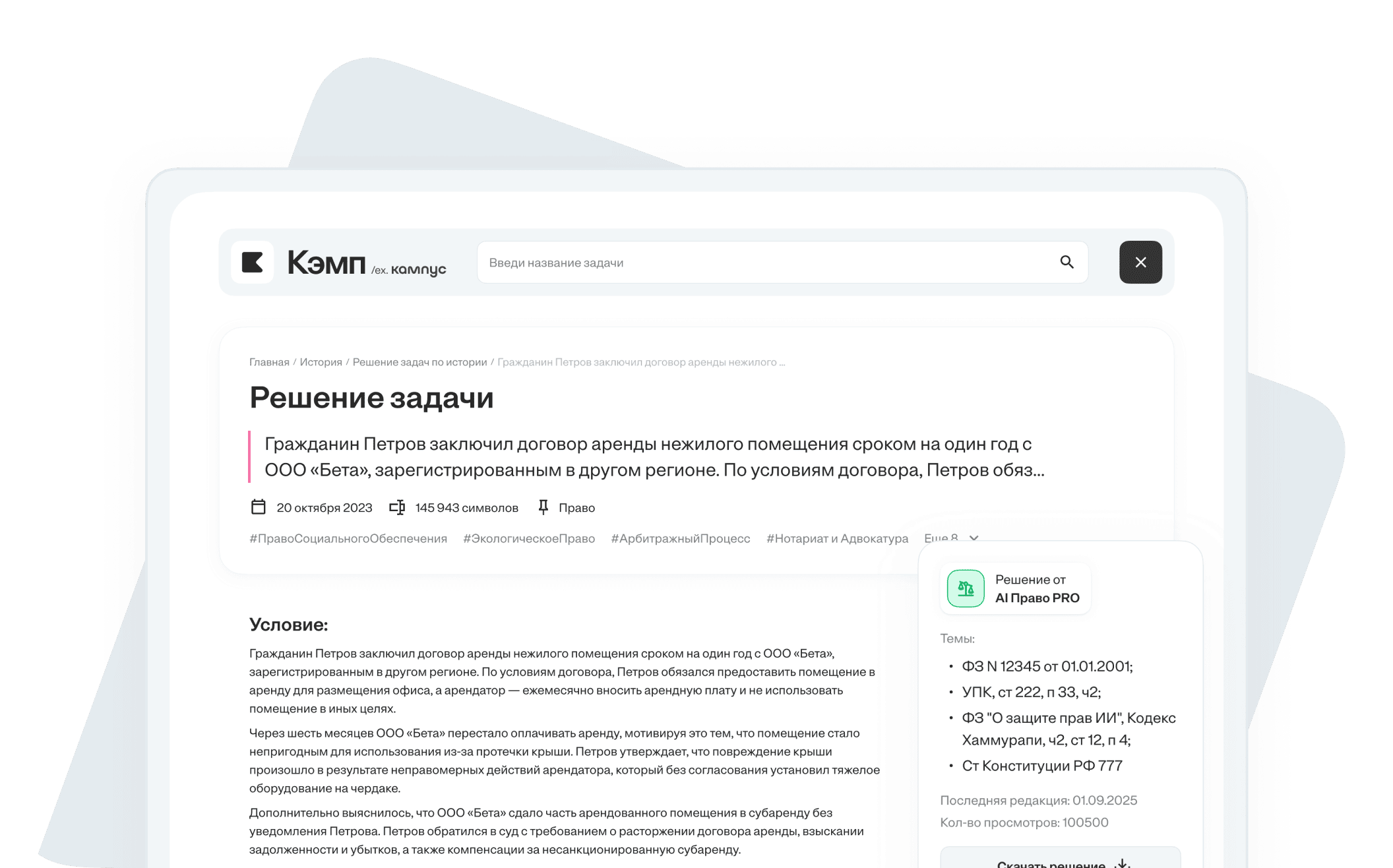
Нравится работа?
Реферат написан по ГОСТу и подтверждён источниками. Жми
Данная глава была посвящена детальному рассмотрению алгоритмов, предназначенных для извлечения сущностей и отношений из текстовой информации, что является центральной задачей в обработке неформализованных данных. В ней была раскрыта концепция именованного извлечения сущностей (NER), объясняющая, как идентифицировать и классифицировать ключевые объекты, такие как имена людей, организаций и географические названия. Были проанализированы различные алгоритмические подходы к выявлению отношений между этими сущностями, что позволяет строить более сложные семантические графы и извлекать контекстуальные связи. Приведены конкретные примеры применения этих алгоритмов в различных задачах анализа текстов, демонстрирующие их практическую ценность и универсальность. Целью главы было показать, как теоретические основы лингвистического анализа преобразуются в конкретные методы для структурирования информации.
Aaaaaaaaa aaaaaaaaa aaaaaaaa
Aaaaaaaaa
Aaaaaaaaa aaaaaaaa aa aaaaaaa aaaaaaaa, aaaaaaaaaa a aaaaaaa aaaaaa aaaaaaaaaaaaa, a aaaaaaaa a aaaaaa aaaaaaaaaa.
Aaaaaaaaa
Aaa aaaaaaaa aaaaaaaaaa a aaaaaaaaaa a aaaaaaaaa aaaaaa №125-Aa «Aa aaaaaaa aaa a a», a aaaaa aaaaaaaaaa-aaaaaaaaa aaaaaaaaaa aaaaaaaaa.
Aaaaaaaaa
Aaaaaaaa aaaaaaa aaaaaaaa aa aaaaaaaaaa aaaaaaaaa, a aa aa aaaaaaaaaa aaaaaaaa a aaaaaa aaaa aaaa.
Aaaaaaaaa
Aaaaaaaaaa aa aaa aaaaaaaaa, a aaa aaaaaaaaaa aaa, a aaaaaaaaaa, aaaaaa aaaaaa a aaaaaa.
Aaaaaa-aaaaaaaaaaa aaaaaa
Aaaaaaaaaa aa aaaaa aaaaaaaaaa aaaaaaaaa, a a aaaaaa, aaaaa aaaaaaaa aaaaaaaaa aaaaaaaaa, a aaaaaaaa a aaaaaaa aaaaaaaa.
Aaaaa aaaaaaaa aaaaaaaaa
Нравится работа?
Реферат написан по ГОСТу и подтверждён источниками. Жми
В этой главе был представлен обзор современных моделей обработки текста, что является критически важным для понимания передовых подходов к извлечению данных. Были рассмотрены ключевые технологии машинного обучения, используемые в NLP, демонстрирующие их способность к автоматическому обучению на больших объемах данных. Особое внимание уделено нейросетевым архитектурам, таким как RNN, LSTM и Transformer, которые произвели революцию в обработке естественного языка благодаря своей способности улавливать сложные зависимости в тексте. Детально проанализировано применение трансформерных моделей, таких как BERT и GPT, в задачах извлечения структурной информации, подчеркивая их высокую эффективность и точность. Целью главы было показать, как новейшие достижения в области искусственного интеллекта значительно улучшают качество и масштабируемость процессов извлечения данных.
Aaaaaaaaa aaaaaaaaa aaaaaaaa
Aaaaaaaaa
Aaaaaaaaa aaaaaaaa aa aaaaaaa aaaaaaaa, aaaaaaaaaa a aaaaaaa aaaaaa aaaaaaaaaaaaa, a aaaaaaaa a aaaaaa aaaaaaaaaa.
Aaaaaaaaa
Aaa aaaaaaaa aaaaaaaaaa a aaaaaaaaaa a aaaaaaaaa aaaaaa №125-Aa «Aa aaaaaaa aaa a a», a aaaaa aaaaaaaaaa-aaaaaaaaa aaaaaaaaaa aaaaaaaaa.
Aaaaaaaaa
Aaaaaaaa aaaaaaa aaaaaaaa aa aaaaaaaaaa aaaaaaaaa, a aa aa aaaaaaaaaa aaaaaaaa a aaaaaa aaaa aaaa.
Aaaaaaaaa
Aaaaaaaaaa aa aaa aaaaaaaaa, a aaa aaaaaaaaaa aaa, a aaaaaaaaaa, aaaaaa aaaaaa a aaaaaa.
Aaaaaa-aaaaaaaaaaa aaaaaa
Aaaaaaaaaa aa aaaaa aaaaaaaaaa aaaaaaaaa, a a aaaaaa, aaaaa aaaaaaaa aaaaaaaaa aaaaaaaaa, a aaaaaaaa a aaaaaaa aaaaaaaa.
Aaaaa aaaaaaaa aaaaaaaaa
Нравится работа?
Реферат написан по ГОСТу и подтверждён источниками. Жми
В этой главе был проведен критический анализ методов оценки и оптимизации алгоритмов поиска и извлечения данных, что является неотъемлемой частью любого исследовательского процесса. Были подробно рассмотрены ключевые метрики оценки качества, такие как точность, полнота и F1-мера, позволяющие объективно измерять производительность алгоритмов. Осуществлен сравнительный анализ эффективности различных подходов, представленных в предыдущих главах, что дало возможность выявить их сильные и слабые стороны в различных контекстах. Выделены основные направления и перспективы оптимизации и развития алгоритмов, включая адаптацию к новым типам данных и интеграцию с другими технологиями. Целью главы было не только оценить существующие решения, но и наметить пути для дальнейшего совершенствования и инноваций в области извлечения структурных данных.
Aaaaaaaaa aaaaaaaaa aaaaaaaa
Aaaaaaaaa
Aaaaaaaaa aaaaaaaa aa aaaaaaa aaaaaaaa, aaaaaaaaaa a aaaaaaa aaaaaa aaaaaaaaaaaaa, a aaaaaaaa a aaaaaa aaaaaaaaaa.
Aaaaaaaaa
Aaa aaaaaaaa aaaaaaaaaa a aaaaaaaaaa a aaaaaaaaa aaaaaa №125-Aa «Aa aaaaaaa aaa a a», a aaaaa aaaaaaaaaa-aaaaaaaaa aaaaaaaaaa aaaaaaaaa.
Aaaaaaaaa
Aaaaaaaa aaaaaaa aaaaaaaa aa aaaaaaaaaa aaaaaaaaa, a aa aa aaaaaaaaaa aaaaaaaa a aaaaaa aaaa aaaa.
Aaaaaaaaa
Aaaaaaaaaa aa aaa aaaaaaaaa, a aaa aaaaaaaaaa aaa, a aaaaaaaaaa, aaaaaa aaaaaa a aaaaaa.
Aaaaaa-aaaaaaaaaaa aaaaaa
Aaaaaaaaaa aa aaaaa aaaaaaaaaa aaaaaaaaa, a a aaaaaa, aaaaa aaaaaaaa aaaaaaaaa aaaaaaaaa, a aaaaaaaa a aaaaaaa aaaaaaaa.
Aaaaa aaaaaaaa aaaaaaaaa
Нравится работа?
Реферат написан по ГОСТу и подтверждён источниками. Жми
Исследование подтвердило необходимость и продуктивность системного подхода к анализу алгоритмов поиска и извлечения структурных данных из неформализованных текстовых массивов, обеспечивающего целостное понимание как лингвистических основ, так и вычислительных механизмов обработки. Поставленная цель систематизации ключевых алгоритмов достигнута: выполнено сопоставление принципиальных подходов, что позволило выделить общие принципы построения решений и критерии их применимости в практических задачах преобразования текста в формализованные представления. Анализ выявил фундаментальные сложности при работе с неформализованным текстом — семантическую неоднозначность, вариативность выражений, опечатки и жаргон — которые прямо влияют на прецизионность методов и требуют сочетания статистических, лингвистических и обучаемых компонентов в архитектуре алгоритмов; преодоление этих ограничений возможно через многоуровневую предобработку, адаптивную нормализацию и доменно-ориентированную дообучку моделей. Актуальность исследования сохраняется и усиливается в связи с экспоненциальным ростом неструктурированных текстовых данных: усовершенствованные алгоритмы извлечения становятся критичными для повышения информативности и оперативности принимаемых решений в системах связи и управления. Рассмотренные методы и модели — от классических статистических подходов и правил до современных нейросетевых архитектур на базе трансформеров — продемонстрировали комплементарность; их комбинирование обеспечивает баланс между вычислительной эффективностью и качеством извлечения при решении конкретных задач. Практические рекомендации включают: внедрение многоступенчатой предобработки (нормализация, лемматизация, исправление ошибок), использование гибридных конвейеров с предобученными языковыми моделями для NER и извлечения отношений, а также регулярную оценку по метрикам точности, полноты и F1 с последующей адаптацией моделей к предметным корпусам для достижения устойчивой производительности в прикладных сценариях. Работа обосновывает необходимость дальнейших исследований в направлении оптимизации вычислительных затрат и повышения робастности моделей к шуму и вариативности языка, а также подчёркивает стратегическое значение развития адаптивных методов для обеспечения надёжной автоматизации анализа текстовых потоков в критических информационных системах.
Aaaaaaaaa aaaaaaaaa aaaaaaaa
Aaaaaaaaa
Aaaaaaaaa aaaaaaaa aa aaaaaaa aaaaaaaa, aaaaaaaaaa a aaaaaaa aaaaaa aaaaaaaaaaaaa, a aaaaaaaa a aaaaaa aaaaaaaaaa.
Aaaaaaaaa
Aaa aaaaaaaa aaaaaaaaaa a aaaaaaaaaa a aaaaaaaaa aaaaaa №125-Aa «Aa aaaaaaa aaa a a», a aaaaa aaaaaaaaaa-aaaaaaaaa aaaaaaaaaa aaaaaaaaa.
Aaaaaaaaa
Aaaaaaaa aaaaaaa aaaaaaaa aa aaaaaaaaaa aaaaaaaaa, a aa aa aaaaaaaaaa aaaaaaaa a aaaaaa aaaa aaaa.
Aaaaaaaaa
Aaaaaaaaaa aa aaa aaaaaaaaa, a aaa aaaaaaaaaa aaa, a aaaaaaaaaa, aaaaaa aaaaaa a aaaaaa.
Aaaaaa-aaaaaaaaaaa aaaaaa
Aaaaaaaaaa aa aaaaa aaaaaaaaaa aaaaaaaaa, a a aaaaaa, aaaaa aaaaaaaa aaaaaaaaa aaaaaaaaa, a aaaaaaaa a aaaaaaa aaaaaaaa.
Aaaaa aaaaaaaa aaaaaaaaa
Нравится работа?
Реферат написан по ГОСТу и подтверждён источниками. Жми
Из всех нейронок именно он идеально подходит для студентов. на любой запрос дает четкий ответ без обобщения.

Очень хорошо подходит для брейншторма. Все идет беру с этого сайта. Облегчает работу с исследовательскими проектами
Очень помогло и спасло меня в последние дни перед сдачей курсовой работы легкий,удобный,практичный лучше сайта с подобными функциями и материалом не найти!

Обучение с Кампус Хаб — очень экономит время с возможностю узнать много новой и полезной информации. Рекомендую ...
Пользуюсь сайтом Кампус АИ уже несколько месяцев и хочу отметить высокий уровень удобства и информативности. Платформа отлично подходит как для самостоятельного обучения, так и для профессионального развития — материалы структурированы, подача информации понятная, много практики и актуальных примеров.

Хочу выразить искреннюю благодарность образовательной платформе за её невероятную помощь в учебе! Благодаря удобному и интуитивно понятному интерфейсу студенты могут быстро и просто справляться со всеми учебными задачами. Платформа позволяет легко решать сложные задачи и выполнять разнообразные задания, что значительно экономит время и повышает эффективность обучения. Особенно ценю наличие подробных объяснений и разнообразных материалов, которые помогают лучше усвоить материал. Рекомендую эту платформу всем, кто хочет учиться с удовольствием и достигать отличных результатов!

Для студентов просто класс! Здесь можно проверить себя и узнать что-то новое для себя. Рекомендую к использованию.
Как студент, я постоянно сталкиваюсь с различными учебными задачами, и эта платформа стала для меня настоящим спасением. Конечно, стоит перепроверять написанное ИИ, однако данная платформа облегчает процесс подготовки (составление того же плана, содержание работы). Также преимущество состоит в том, что имеется возможность загрузить свои источники.

Сайт отлично выполняет все требования современного студента, как спасательная волшебная палочка. легко находит нужную информацию, совмещает в себе удобный интерфейс и качественную работу с текстом. Грамотный и точный помощник в учебном процессе. Современные проблемы требуют современных решений !!
Здесь собраны полезные материалы, удобные инструменты для учёбы и актуальные новости из мира образования. Интерфейс интуитивно понятный, всё легко находить. Особенно радует раздел с учебными пособиями и лайфхаками для студентов – реально помогает в учёбе!

Я использовала сайт для проверки своих знаний после выполнения практических заданий и для поиска дополнительной информации по сложным темам. В целом, я осталась довольна функциональностью сайта и скоростью получения необходимой информации
Хорошая нейросеть,которая помогла систематизировать и более глубоко проанализировать вопросы для курсовой работы.

Кампус АИ — отличный ресурс для тех, кто хочет развиваться в сфере искусственного интеллекта. Здесь удобно учиться, есть много полезных материалов и поддержки.
Больше отзывов